사이트 크롤링 하는 방법
마케터라면 익숙할 크롤링.
하지만 어떻게 해야하는지 찾다가 멘붕에 많이 빠지게 되는 단어다.
솔직히 크롤링이란 단어만 외친지 10년은 되었는데, 솔직히 하는 방법을 깨우친건 지금으로부터 2~3년 전쯤이다.
그리고 솔직히 하는 방법은 간단하다.
우선 아래 2개 파이썬 패키지를 설치한다.
requests
BrautifulSoup
기본 문구는 다음과 같다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('크롤링할 페이지url',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')** 나는 지니뮤직 top200을 가져와 볼거다. 그렇기에 위에 있는 [크롤링할 페이지url] 부분에 이 url을 집어넣는다.
▶︎ https://www.genie.co.kr/chart/top200?ditc=M&rtm=N
지니차트>월간 - 지니
AI기반 감성 음악 추천
www.genie.co.kr
가져올 내용은 아래 3가지이다. (곡 제목, 아티스트명, 현재 순위)
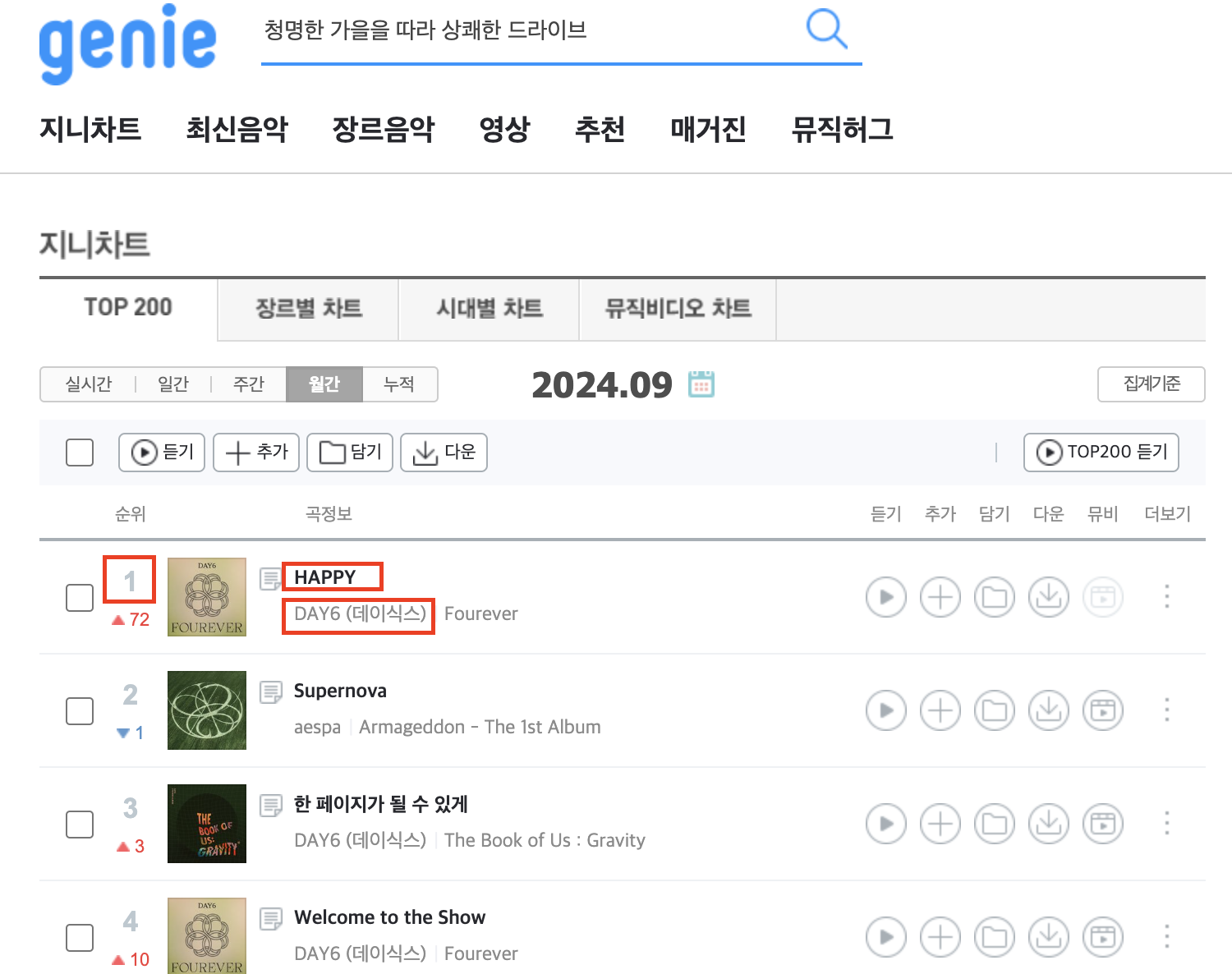
자, 저 위치에 있는 정보를 가져오려고 한다.
그렇다면, 저 위치를 식별할 수 있어야 한다.
어떻게?
1. id값
2. class값
3. 속성값(alt 등)
4. css selector (코딩된 위치)
다양한 방법들이 있겠지만, 기본적으로 저 4개를 많이 사용할거다. 특히 마케터라면 gtm을 다룰 때, id, class, css selector는 정말 많이 사용했을 거다. 하지만 내가 직접 운영하는 사이트면 몰라도, 외부몰은 대개 내가 원하는 위치에 id, class 등이 붙어있는 경우가 없기에, css selector를 주로 사용한다.
[beautifulsoup에서 정의된 select 방법]
# 선택자를 사용하는 방법 (css selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
그런 의미로 각각의 정보를 css selector로 확인한 결과, 다음과 같다.
곡제목 - #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
아티스트 - #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
순위 - #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
이에 아래와 같이 하면 된다.
musics = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for music in musics:
rank = music.select_one('td.number')
title = music.select_one('td.info > a.title.ellipsis')
artist = music.select_one('td.info > a.artist.ellipsis')
print(rank, title, artist)
그럼 순위(rank), 제목(title), 아티스트명(artist)가 출력될 거다.
근데 아마 이상하게 출력될거다. (대부분 크롤링 할 때 구조가 지들맘대로라 깔끔하게 나오지 않는다)
그래서 출력된 걸 보면서 수정해야한다.
지니뮤직 사이트의 경우 아래와 같이 수정했다.
musics = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for music in musics:
rank = music.select_one('td.number').text[0:2].strip()
title = music.select_one('td.info > a.title.ellipsis').text.strip()
artist = music.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, artist)의미는 각각 다음과 같다.
1) .text
.text는 문자열로 출력하는 것을 말하며, .text[0:2]는 2번째 문자열까지 출력하라고 표시한 것이다. 순위의 경우 상승/하락까지 같이 표시가 되어서, 앞에서 2글자까지만 출력되도록 한 것이다.
[문자열 슬라이싱 예시]
string = "bongdroid"
print(string[0:4]) #bong 출력
print(string[2:6]) #ngdr 출력
print(string[-1]) #d 출력(맨 마지막 문자)
print(string[-5:]) #droid 출력(맨 마지막 5개 문자)
2) .strip()
.strip은 문자열 및 공백을 제거하는 것이다. 위 지니뮤직 사이트에선 공백만 지우면 되었기에 .strip()이라 표현한 것이다.
string = "example@gmail.com"
print(string.strip()) # 1. 공백제거하기 ▶︎ example@gmail.com
print(string.strip('m')) # 2. 특정문자제거하기1 ▶︎ example@gmail.co
print(string.strip('e')) # 3. 특정문자제거하기2 ▶︎ xample@gmail.com
print(string.strip('cmoez.')) # 4. 특정문자제거하기3 ▶︎ xample@gmail